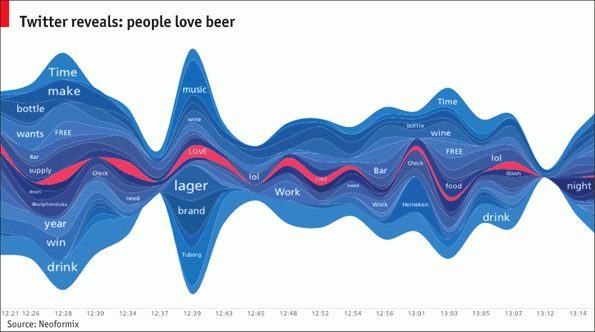
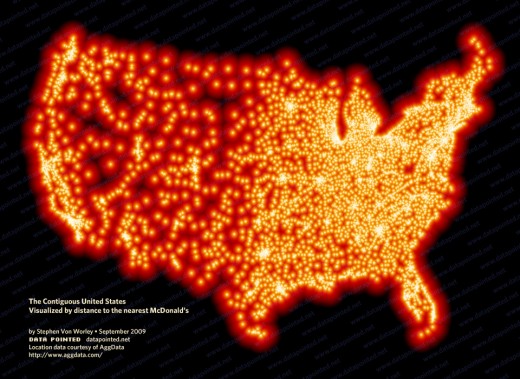
Category: Uncategorized
-
Spatial ecological networks – where physics, ecology, geography and computational science meet
-
Full access to the Twitter API in Matlab via R
-
“Sipping from the fire hose” – sampling Twitter streams
-
Financial conflicts of interest in guidelines
-
Australians’ views of our own health system
-
The Framingham Study, fast food access, and BMI